AutoEncoding collective variables¶
![]()
Import¶
[1]:
# Colab setup
import os
if os.getenv("COLAB_RELEASE_TAG"):
import subprocess
subprocess.run('wget https://raw.githubusercontent.com/luigibonati/mlcolvar/main/colab_setup.sh', shell=True)
cmd = subprocess.run('bash colab_setup.sh TUTORIAL', shell=True, stdout=subprocess.PIPE)
print(cmd.stdout.decode('utf-8'))
# IMPORT PACKAGES
import torch
import lightning
import numpy as np
import matplotlib.pyplot as plt
# IMPORT HELPER FUNCTIONS
from mlcolvar.utils.plot import muller_brown_potential, plot_isolines_2D, plot_metrics
/Users/luigi/opt/anaconda3/envs/pytorch13/lib/python3.9/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Muller-Brown potential (high-temperature)¶
Load MD data¶
[2]:
from mlcolvar.io import create_dataset_from_files
from mlcolvar.data import DictModule
filenames = [ "data/muller-brown/unbiased/high-temp/COLVAR" ]
# load data into dataset
dataset, df = create_dataset_from_files(filenames,filter_args={'regex':'p.x|p.y'},return_dataframe=True)
# create datamodule
datamodule = DictModule(dataset,lengths=[0.8,0.2])
Class 0 dataframe shape: (5001, 11)
- Loaded dataframe (5001, 11): ['time', 'p.x', 'p.y', 'p.z', 'ene', 'pot.bias', 'pot.ene_bias', 'lwall.bias', 'lwall.force2', 'uwall.bias', 'uwall.force2']
- Descriptors (5001, 2): ['p.x', 'p.y']
[3]:
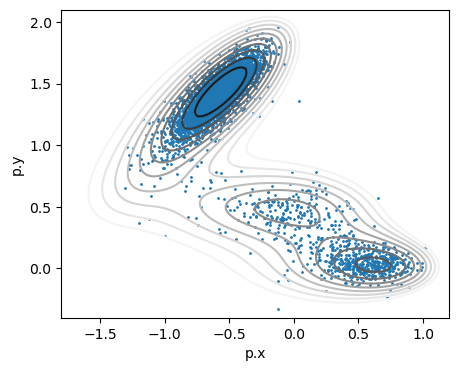
fig,ax = plt.subplots(figsize=(5,4),dpi=100)
# ploy MB isolines
plot_isolines_2D(muller_brown_potential,mode='contour',levels=np.linspace(0,24,12),ax=ax)
# plot points colored according to labels
df.plot.scatter('p.x','p.y',s=1,cmap='fessa',ax=ax)
/Users/luigi/opt/anaconda3/envs/pytorch13/lib/python3.9/site-packages/pandas/plotting/_matplotlib/core.py:1259: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
scatter = ax.scatter(
[3]:
<Axes: xlabel='p.x', ylabel='p.y'>
Define model¶
[4]:
from mlcolvar.cvs import AutoEncoderCV
n_components = 1
encoder_layers = [2,10,10,n_components]
nn_args = {'activation': 'shifted_softplus'}
options= {'encoder': nn_args, 'decoder': nn_args }
model = AutoEncoderCV (encoder_layers, options=options )
model
[4]:
AutoEncoderCV(
(normIn): Normalization(in_features=2, out_features=2, mode=mean_std)
(encoder): FeedForward(
(nn): Sequential(
(0): Linear(in_features=2, out_features=10, bias=True)
(1): Shifted_Softplus(beta=1, threshold=20)
(2): Linear(in_features=10, out_features=10, bias=True)
(3): Shifted_Softplus(beta=1, threshold=20)
(4): Linear(in_features=10, out_features=1, bias=True)
)
)
(decoder): FeedForward(
(nn): Sequential(
(0): Linear(in_features=1, out_features=10, bias=True)
(1): Shifted_Softplus(beta=1, threshold=20)
(2): Linear(in_features=10, out_features=10, bias=True)
(3): Shifted_Softplus(beta=1, threshold=20)
(4): Linear(in_features=10, out_features=2, bias=True)
)
)
)
VAE
from mlcolvar.cvs import VariationalAutoEncoderCV n_components = 1 encoder_layers = [2,10,10] decoder_layers = [2] nn_args = {'activation': 'elu'} options= {'encoder': nn_args, 'decoder': nn_args } model = VariationalAutoEncoderCV(n_cvs = n_components, encoder_layers = encoder_layers, decoder_layers= decoder_layers, options=options ) modelDefine Trainer & Fit¶
[5]:
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
from mlcolvar.utils.trainer import MetricsCallback
# define callbacks
metrics = MetricsCallback()
early_stopping = EarlyStopping(monitor="valid_loss", min_delta=1e-5, patience=10)
# define trainer
trainer = lightning.Trainer(callbacks=[metrics, early_stopping],
max_epochs=None, logger=None, enable_checkpointing=False)
# fit
trainer.fit( model, datamodule )
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/Users/luigi/opt/anaconda3/envs/pytorch13/lib/python3.9/site-packages/lightning/trainer/connectors/logger_connector/logger_connector.py:67: UserWarning: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `lightning` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
warning_cache.warn(
/Users/luigi/opt/anaconda3/envs/pytorch13/lib/python3.9/site-packages/lightning/loops/utilities.py:70: PossibleUserWarning: `max_epochs` was not set. Setting it to 1000 epochs. To train without an epoch limit, set `max_epochs=-1`.
rank_zero_warn(
| Name | Type | Params | In sizes | Out sizes
-----------------------------------------------------------------
0 | normIn | Normalization | 0 | [2] | [2]
1 | encoder | FeedForward | 151 | [2] | [1]
2 | decoder | FeedForward | 152 | ? | ?
-----------------------------------------------------------------
303 Trainable params
0 Non-trainable params
303 Total params
0.001 Total estimated model params size (MB)
/Users/luigi/opt/anaconda3/envs/pytorch13/lib/python3.9/site-packages/lightning/loops/fit_loop.py:280: PossibleUserWarning: The number of training batches (1) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
rank_zero_warn(
Epoch 999: 100%|██████████| 1/1 [00:00<00:00, 8.18it/s, v_num=3]
`Trainer.fit` stopped: `max_epochs=1000` reached.
Epoch 999: 100%|██████████| 1/1 [00:00<00:00, 6.24it/s, v_num=3]
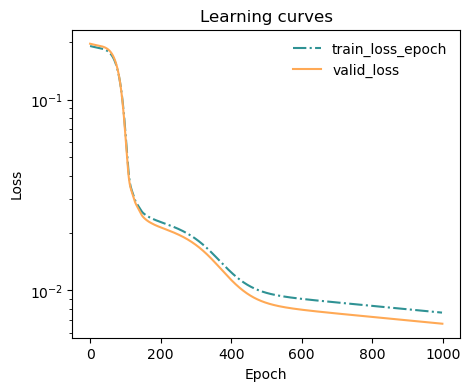
Learning curve
[6]:
model.eval()
ax = plot_metrics(metrics.metrics,
keys=['train_loss_epoch','valid_loss'],
linestyles=['-.','-'], colors=['fessa1','fessa5'],
yscale='log')
Normalize output after training
[7]:
from mlcolvar.core.transform import Normalization
from mlcolvar.core.transform.utils import Statistics
X = dataset[:]['data']
with torch.no_grad():
model.postprocessing = None # reset
s = model(torch.Tensor(X))
norm = Normalization(n_components, mode='min_max', stats = Statistics(s) )
model.postprocessing = norm
#print(Statistics(s))
Analysis of the CV¶
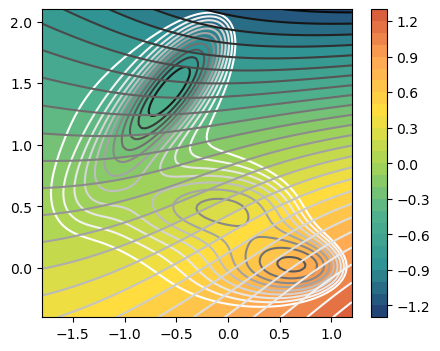
CVs isolines
[8]:
fig,axs = plt.subplots( 1, n_components, figsize=(5*n_components,4) )
if n_components == 1:
axs = [axs]
for i in range(n_components):
ax = axs[i]
plot_isolines_2D(muller_brown_potential,levels=np.linspace(0,24,12),mode='contour',ax=ax)
plot_isolines_2D(model, component=i, levels=25, ax=ax)
plot_isolines_2D(model, component=i, mode='contour', levels=25, ax=ax)
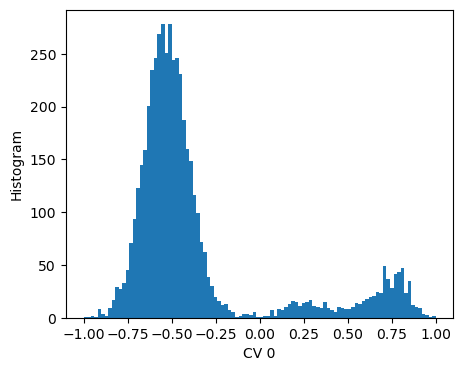
CV histogram
[9]:
fig,axs = plt.subplots(1,n_components,figsize=(5*n_components,4))
if n_components == 1:
axs = [axs]
X = dataset[:]['data']
with torch.no_grad():
s = model(torch.Tensor(X)).numpy()
for i,ax in enumerate(axs):
ax.hist(s[:,i],bins=100)
ax.set_xlabel(f'CV {i}')
ax.set_ylabel('Histogram')
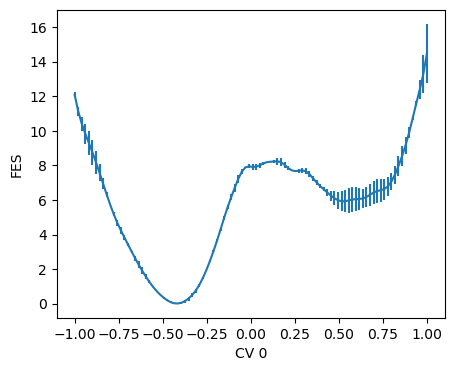
Free energy profile
[ ]:
from mlcolvar.utils.fes import compute_fes
fig,axs = plt.subplots(1,n_components,figsize=(5*n_components,4))
if n_components == 1:
axs = [axs]
X = dataset[:]['data']
model.eval()
with torch.no_grad():
s = model(torch.Tensor(X)).numpy()
for i,ax in enumerate(axs):
fes,grid,bounds,std = compute_fes(s[:,i], kbt=2.5, plot=True, scale_by='range', bandwidth=0.02, blocks=2, plot_max_fes=20, ax=ax )
ax.set_xlabel(f'CV {i}')