Deep-LDA: Neural network-based discriminant CVs¶
Reference paper: Bonati, Rizzi and Parrinello, JCPL (2020) [arXiv].
![]()
Introduction¶
The aim of this tutorial is to illustrate how we can design collective variables in a data-driven way, starting from local fluctuations of a set of physical descriptors in the metastable states. For applying these methods we will only need to have samples from different metastable states (typically obtained by MD simulations starting from e.g. reactants and products).
Linear Discriminant Analysis
To this extent, we resort to a statistical method called Linear Discriminant Analysis (LDA). LDA searches for the linear projection \(s=\bar{w}^T x\) of the input data \(x\) such that the classes are maximally separated. The parameters are obtained by maximizing the so called Fisher’s ratio of the between-class variance \(\mathbf{S}_b\) to the within-class variance \(\mathbf{S}_w\)
The within class variance (or scatter) matrix is defined as the average of class covariances:
while the between class one is defined as the covariance of class means \(\boldsymbol{\mu}_c\):
where \(\boldsymbol{\mu}\) denotes their average.
In the simple case of two classes (states) A and B these can be easily computed from the mean and covariance matrices of the data in the states:

The discriminant components \(\{\mathbf{v}_i\}\) are obtained by solving the generalized eigenvalue problems: \begin{equation} \mathbf{S}_b\mathbf{v}_i = \mathbf{S}_w\lambda_i^{(lda)} \mathbf{v}_i \end{equation} where the eigenvalues \(\lambda_i^{(lda)}\) measure the amount of separation between the states along the i-th component. Note that for LDA the number of output components is determined by the number of non-zero eigenvalues which is equal to the number of classes \(n_C - 1\).
An harmonic variant, called HLDA, has been proposed for CV discovery, where the within-scatter matrix is calculated from the harmonic mean of the class covariances:
Neural networks-based LDA

A non-linear generalization of LDA can be obtained by transforming the input features via a neural network (NN), and then performing LDA on the NN outputs. In this way, we are transforming the input space in such a way that the discrimination between the states is maximal. During the training, the parameters are optimized to maximize the LDA eigenvalues \(\mathbf\lambda\):
\begin{equation} \mathcal{L}_{DeepLDA}=-\sum_{c=1} ^{n_c-1} \lambda_c^{(lda)} + \text{reg}_{lor} \end{equation} with \(\text{reg}_{lor}=\alpha \left( 1+( \mathbb{E}\left[||\mathbf{s}||^2\right]-1)^2 \right)^{-1}\) being a Lorentzian regularization acting on the average of the output CVs keeping its norm close to 1, to make the objective function bounded. Note that, in the case of two states, Fisher’s loss is equal to the single eigenvalue, while in the multiclass one, we have \(n_C-1\) of them. In the latter case, we could also maximize another (monotonic) function of the eigenvalues, such as the sum of squares or even just the smallest eigenvalue.
Note that to stabilize the learning we also regularize the calculation of \(S_w\) by adding the identity matrix multiplied by a parameter \(\beta\), as: \(S_w '= S_w+\beta\mathbb{1}\) . The two regularization parameters \(\alpha\) and \(\beta\) are not independent, as the former affects the numerator of the Fisher’s ratio above and the latter the denominator. Hence, in the following, we will choose only \(\beta\) and set \(\alpha=\frac{2}{\beta}\).
Setup¶
[1]:
# Colab setup
import os
if os.getenv("COLAB_RELEASE_TAG"):
import subprocess
subprocess.run('wget https://raw.githubusercontent.com/luigibonati/mlcolvar/main/colab_setup.sh', shell=True)
cmd = subprocess.run('bash colab_setup.sh TUTORIAL', shell=True, stdout=subprocess.PIPE)
print(cmd.stdout.decode('utf-8'))
# IMPORT PACKAGES
import torch
import lightning
import numpy as np
import matplotlib.pyplot as plt
# IMPORT HELPER FUNCTIONS
from mlcolvar.utils.plot import muller_brown_potential, plot_isolines_2D, plot_metrics
# Set seed for reproducibility
torch.manual_seed(42)
/home/lbonati@iit.local/software/anaconda3/envs/pytorch/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
[1]:
<torch._C.Generator at 0x7fe974610370>
Muller-Brown potential¶
In this first example we train a CV for the Muller-Brown 2D potential, using labeled samples collected from MD simulations started in the two basins.
Load MD data¶
[2]:
from mlcolvar.utils.io import create_dataset_from_files
from mlcolvar.data import DictModule
n_states = 2
filenames = [ f"data/muller-brown/unbiased/state-{i}/COLVAR" for i in range(n_states) ]
# load dataset
dataset, df = create_dataset_from_files(filenames,return_dataframe=True, filter_args={'regex':'p.x|p.y'})
Class 0 dataframe shape: (2001, 13)
Class 1 dataframe shape: (2001, 13)
- Loaded dataframe (4002, 13): ['time', 'p.x', 'p.y', 'p.z', 'ene', 'pot.bias', 'pot.ene_bias', 'lwall.bias', 'lwall.force2', 'uwall.bias', 'uwall.force2', 'walker', 'labels']
- Descriptors (4002, 2): ['p.x', 'p.y']
[3]:
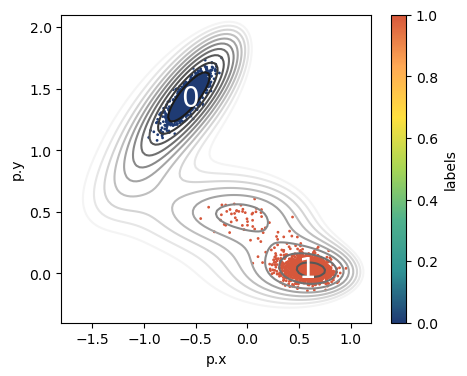
fig,ax = plt.subplots(figsize=(5,4),dpi=100)
# ploy MB isolines
plot_isolines_2D(muller_brown_potential,mode='contour',levels=np.linspace(0,24,12),ax=ax)
# plot points colored according to labels
df.plot.scatter('p.x','p.y',c='labels',s=1,cmap='fessa',ax=ax)
# draw state labels
for i in range(n_states):
df_g = df.groupby('labels').mean()
ax.text(x = df_g['p.x'].values[i]-0.075,
y = df_g['p.y'].values[i]-0.075,
s = str(i), size=20, color='white')
Prepare dataset
[4]:
# get inputs X and labels
X = dataset[:]['data']
labels = dataset[:]['labels']
print('X:',X.shape)
print('labels:',labels.shape)
X: torch.Size([4002, 2])
labels: torch.Size([4002])
LDA¶
We can optimize an LDA variable from the core.stats module. We only need to initialize it and call the compute method.
[5]:
from mlcolvar.core.stats import LDA
# define LDA object
lda = LDA(in_features=X.shape[1], n_states=n_states, mode='standard')
# compute vectors that most discriminate the states
eigvals, eigvecs = lda.compute(X,labels)
The discriminant component is given by the linear combination along the eigenvector, with coefficients:
[6]:
print(eigvecs)
tensor([[ 0.3874],
[-0.9219]])
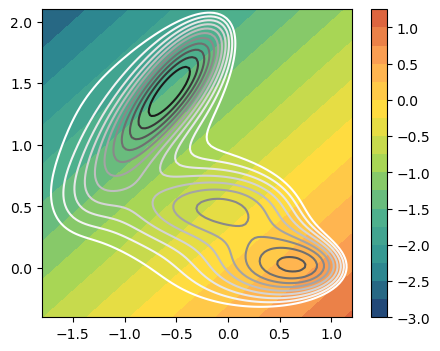
The direction can be easily visualized in the 2D space by plotting its isolines together with the ones of the potential. Remember that the additional force acting on the CV will drive the system in the direction orthogonal to the isolines of the CVs.
[7]:
# Inspect linear combination vs potential
n_components=n_states-1
fig,axs = plt.subplots( 1, n_components, figsize=(5*n_components,4) )
if n_components == 1:
axs = [axs]
for i in range(n_components):
ax = axs[i]
plot_isolines_2D(muller_brown_potential,levels=np.linspace(0,24,12),mode='contour',ax=ax)
plot_isolines_2D(lda, component=i, levels=15, ax=ax)

HLDA (harmonic variant)¶
To use the harmonic variant (in which the within-scatter matrix is calculated with an harmonic mean), we just need to select the mode=harmonic when initializing the CV.
[8]:
# define HLDA object
hlda = LDA(in_features=X.shape[1], n_states=n_states, mode='harmonic')
# compute vectors that most discriminate the states
eigvals, eigvecs = hlda.compute(X,labels)
[9]:
# Inspect linear combination vs potential
n_components=n_states-1
fig,axs = plt.subplots( 1, n_components, figsize=(5*n_components,4) )
if n_components == 1:
axs = [axs]
for i in range(n_components):
ax = axs[i]
plot_isolines_2D(muller_brown_potential,levels=np.linspace(0,24,12),mode='contour',ax=ax)
plot_isolines_2D(hlda, component=i, levels=15, ax=ax)
Deep-LDA: maximizing LDA eigenvalues¶
To optimize a NN to maximize the discriminative power of LDA we need to wrap the dataset inside a datamodule and define the corresponding DeepLDA CV.
Create datamodule¶
[10]:
# create datamodule for trainere
datamodule = DictModule(dataset,lengths=[0.8,0.2])
datamodule
[10]:
DictModule(dataset -> DictDataset( "data": [4002, 2], "labels": [4002] ),
train_loader -> DictLoader(length=0.8, batch_size=0, shuffle=True),
valid_loader -> DictLoader(length=0.2, batch_size=0, shuffle=True))
Define model¶
[11]:
from mlcolvar.cvs import DeepLDA
n_components = n_states-1
nn_layers = [2,30,30,5]
nn_args = {'activation': 'relu'}
options= {'nn': nn_args}
# MODEL
model = DeepLDA(nn_layers,n_states=n_states, options=options)
Define Trainer & Fit¶
[12]:
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
from mlcolvar.utils.trainer import MetricsCallback
# define callbacks
metrics = MetricsCallback()
early_stopping = EarlyStopping(monitor="valid_eigval_1_epoch", mode='max', min_delta=1e-3, patience=50)
# define trainer
trainer = lightning.Trainer(callbacks=[metrics, early_stopping],
max_epochs=250, logger=None, enable_checkpointing=False)
# fit
trainer.fit( model, datamodule )
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
/home/lbonati@iit.local/software/anaconda3/envs/pytorch/lib/python3.10/site-packages/lightning/pytorch/trainer/connectors/logger_connector/logger_connector.py:67: UserWarning: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `lightning.pytorch` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
warning_cache.warn(
You are using a CUDA device ('NVIDIA GeForce RTX 3090') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | In sizes | Out sizes
-------------------------------------------------------------------------
0 | loss_fn | ReduceEigenvaluesLoss | 0 | ? | ?
1 | norm_in | Normalization | 0 | [2] | [2]
2 | nn | FeedForward | 1.2 K | [2] | [5]
3 | lda | LDA | 0 | [5] | [1]
-------------------------------------------------------------------------
1.2 K Trainable params
0 Non-trainable params
1.2 K Total params
0.005 Total estimated model params size (MB)
/home/lbonati@iit.local/software/anaconda3/envs/pytorch/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py:280: PossibleUserWarning: The number of training batches (1) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
rank_zero_warn(
Epoch 249: 100%|██████████| 1/1 [00:00<00:00, 15.34it/s, v_num=74]
`Trainer.fit` stopped: `max_epochs=250` reached.
Epoch 249: 100%|██████████| 1/1 [00:00<00:00, 13.85it/s, v_num=74]
After the training we can monitor the evolution of the LDA eigenvalue over the epochs.
[13]:
ax = plot_metrics(metrics.metrics,
keys=[x for x in metrics.metrics.keys() if 'valid' in x],#['train_loss_epoch','valid_loss'],
#linestyles=['-.','-'], colors=['fessa1','fessa5'],
yscale='linear')

Analysis of the CV¶
Here we compare the LDA vs DeepLDA CVs through their isolines as well as the histograms of the CVs. The latter is able to maximize the discriminative power of the CVs.
[14]:
fig,axs = plt.subplots( 1, 2, figsize=(5*2,4) )
# LDA
ax = axs[0]
plot_isolines_2D(muller_brown_potential,levels=np.linspace(0,24,12),mode='contour',ax=ax)
plot_isolines_2D(lda, component=i, levels=15, ax=ax)
ax.set_title('LDA')
# Deep-LDA
ax = axs[1]
plot_isolines_2D(muller_brown_potential,levels=np.linspace(0,24,12),mode='contour',ax=ax)
plot_isolines_2D(model, component=i, levels=15, vmin=-1.2,vmax=1.2, ax=ax)
ax.set_title('DeepLDA')
[14]:
Text(0.5, 1.0, 'DeepLDA')

[15]:
fig,axs = plt.subplots( 1, 2, figsize=(5*2,4) )
titles = ['LDA','DeepLDA']
for (m, ax, title) in zip([lda,model],axs,titles):
X = dataset[:]['data']
with torch.no_grad():
s = m(torch.Tensor(X)).numpy()
ax.hist(s[:,0],bins=100)
ax.set_xlabel(f'CV {i}')
ax.set_ylabel('Histogram')
ax.set_title(title)

[ ]: